True programmers work in the command-line ;-)
Some people think GUIs have replaced the command-line. But they have not, they are complementary. Some things can still be done better and easier in the command-line, for example scripting, and to servers one usually has access via an SSH terminal only. But there is more! This blog will describe a few very convenient commands for software developers. All of it works in the Bash shell (common on Linux), but most of it works in the Z shell (zsh) as well (common on Mac).
Convenient Bash Keyboard Shortcuts and history
-
Crtl-A,Home (Linux): Go to the beginning of the line -
Ctrl-E,End (Linux): Go to the end of the line -
Ctrl-K,Ctrl-Del (Linux): Clears line after and including the cursor -
Ctrl-U (does not work in zsh): Clears line before and excluding the cursor -
Ctrl-W: Delete last word to left of the cursor -
Ctrl-Left (Linux),Option-Left (Mac): Jump word to the left -
Ctrl-Right (Linux),Option-Right (Mac): Jump word to the right -
Up: Get previous command -
Down: Get next command -
Tab: Auto complete -
Ctrl-R: search through previous commands -
Ctrl-Shift-C (Linux),Cmd-C (Mac): copy selected text -
Ctrl-Shift-V (Linux),Cmd-V (Mac): paste selected text -
Shift-Insert (Linux): copy and paste selected text
For more sophisticated retrievals of previous commands checkout the history command.
For example history -200 | grep git checks for the pattern git in the last 200 commands.
Analysing files with less is more, tail -f, grep
For viewing the content of files (usually log files) less <filename> is more convenient than more <filename>, hence 'less is more'.
Usually less can handle large file better than your IDE or any other GUI based editor.
To follow the tail of a log file one can use, tail -f <filename>.
To find patterns in one or more files grep is imperative, eg. grep <pattern> <filename.pattern>.
Some useful options of grep:
-
-n,-A,-B: more context -
-v: exclude
You can also combine this into: tail -f <filename> | grep <pattern>.
These commands have many more options, check them out with man <command> or <command> --help or <command> -h.
Hex viewing
To inspect the binary content of a file one can use od -tx1 -c <filename>.
This will display the bytes of the file as hexadecimal numbers.
Recursive commands with xargs
xargs is a very convenient command to pass on arguments from one command to another.
You can for example use it to do a recursive grep of a certain pattern on a selection of files:
find <dir> -name "<filename.pattern>" | xargs grep "<grep.pattern>"Example:
find . -name "*.java" | xargs grep -i "token"To get rid of the Is a directory noise (when your filename pattern matches directory names as well) suffix it with 2>&1 | grep -v 'Is a directory'.
This redirects stderr output to stdout which is where grep operates on, and next we exclude the Is a directory matches.
Example:
find .. -name "build*" | xargs grep -i "token" 2>&1 | grep -v 'Is a directory'Another example of xargs usage, recursively delete a selection of files:
find . -name "*.txt.old" | xargs rmTesting HTTP services with curl
For manually (or with a script) testing web service check out curl. Some examples:
Get the version of myservice:
curl http://127.0.0.1:8080/myservice/versionPost a literal JSON message:
curl -X POST http://127.0.0.1:8080/myservice \
-H "Content-Type: application/json; charset=UTF-8" \
-d '{"key1":"value1", "key2":"value2"}'Post a JSON message from the file message.json:
curl -X POST http://127.0.0.1:8080/myservice \
-H "Content-Type: application/json; charset=UTF-8" \
-d "@message.json"Check services on ports
To see which services are listening to which ports one can use netstat -tulpn.
SSH tunnels
Very often the only access to a server is through SSH. All other ports are closed for security reasons. Now suppose you would like to directly access the database server on a host which can only be accessed from an application server. You do have SSH access to the application server. To connect your local SQL client to the database you can use a tunnel as depicted below. Notice the tunnel is going through instead of under the firewall.
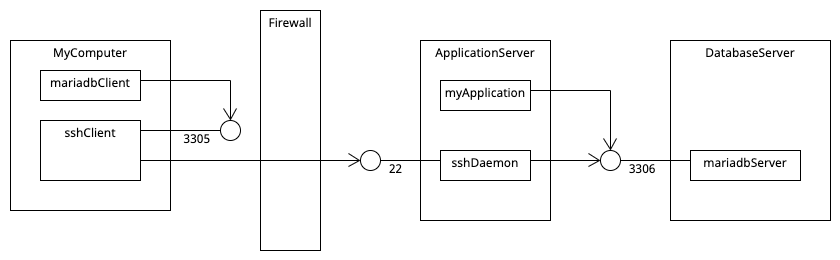
(created with Umletino, source file)
The commands to set up the tunnel and keep it alive, in a terminal:
ssh -L<localPort>:<targetHostName>:<targetPort> [<userName>@]<viaHostName>
watch -n60 pwdAnd in another terminal:
mariadb -u<username> -p<password> -hlocalhost -P<localPort>Notice the watch -n60 pwd command in the SSH session above.
It serves to keep the SSH connection alive, because it may die from an inactivity timeout since you are probably not using that session directly (traffic through the tunnel usually does not count as activity).
Officially you should use settings like
Host *
ServerAliveInterval 60
ServerAliveCountMax 9999
TCPKeepAlive yesin your <home/.ssh/config file. But this very often does not work, hence the watch command.
By the way, if you get tired providing your password when logging in with ssh check out the commands: sshpass, ssh-keygen, and ssh-copy-id <username>@<host>.
Run commands on a remote machine
You can do this in 2 ways.
Use ENDSSH
Create a script containing:
ssh <username>@<remoteHostName> <<'ENDSSH'
#commands to run on remote host
ENDSSHExample:
ssh myname@myserver.services <<'ENDSSH'
echo a1 > /tmp/a1.txt
echo a2 > /tmp/a2.txt
ENDSSHThis will create 2 files on the remove host: /tmp/a1.txt and /tmp/a2.txt.
If your remote commands contain a special character this will probably fail. To solve that use the following approach which is even more elegant.
Use base64
-
Put your commands in a script, eg.
myscript.sh. -
Next run:
MYCOMMAND=`base64 -w0 -i myscript.sh`
ssh <username>@<remoteHostName> "echo $MYCOMMAND | base64 -d | bash"This will also execute the content of myscrip.sh on the remote host.
In fact, with this method the script does not even have to be a script, it can actually be a binary as well!
